Running Local LLMs with Ollama: A Comprehensive Guide
The rise and development of Large Language Models (LLM) have revolutionized the way we interact with computers. These powerful models are capable of understanding, generating human-like text, and even learning from contextual cues. While cloud-based LLMs have their advantages, there are scenarios where running these models locally is beneficial. This is where Ollama steps in, offering a robust framework to deploy and manage local LLMs efficiently.
What is Ollama?
Ollama is a versatile platform designed to simplify the process of running large language models locally. It provides tools and utilities that enable developers to deploy, manage, and interact with LLMs on their own hardware, ensuring data privacy, reducing latency, and eliminating dependency on external services. Whether you’re a researcher, a developer, or an enthusiast, Ollama offers a streamlined approach to harnessing the power of LLMs right on your machine.
Why Run LLMs Locally?
- Data Privacy: Sensitive data stays within your local environment, enhancing security and compliance with data protection regulations.
- Reduced Latency: Local execution can significantly reduce the response time, which is critical for real-time applications.
- Cost Efficiency: Avoid recurring costs associated with cloud-based services by leveraging your existing hardware.
- Customization: Gain complete control over the model and its environment, allowing for deeper customization and optimization.
Setting Up Your Local LLM Environment
Installing Ollama
You can download the executable from Ollama download page for your operating system install it. Once installed Ollama runs on port number 11234.
Once you install ollama, ollama cli is available to you perform various action like
ollama --help
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
Choose an LLM Model
Next decide on the LLM model you want to use. There are various models available like Gemma, Phi3, Llama3.
You can go to Ollama library page to view the readily available LLM models.
Downloading and Running The Model
You can download and start using the model run the following command.
ollama run deepseek-coder
Once the model is downloaded, cli gives the prompt ask the question to the model.
ollama run deepseek-coder
>>> Send a message (/? for help)
Below is the sample chat with LLM model
ollama run deepseek-coder
>>> HI , Who are you?
Hello! I'm an AI programming assistant based on Deepseek's Debate Coder model. My purpose is assist with computer
science related queries such as coding problems and explaining concepts in a simplified manner for beginners or
experts alike who may need to learn something new about the field of Computer Science, Technology etc., by
answering questions you might have during your learning process on this topic!
>>> Send a message (/? for help)
Ollama provides only CLI interface for interacting with LLM models.
If you prefer to have Web UI, you can install web UI called Open Web UI.
Open-WebUI: A User Interface for Your LLMs
Open-WebUI, formerly known as Ollama WebUI, is an extensible and feature-rich self-hosted web interface designed to work seamlessly with Ollama. It offers a ChatGPT-style interface, allowing users to interact with local LLMs in a familiar and intuitive manner. With Open-WebUI, developers can easily deploy and manage language models, providing a seamless and user-friendly experience for both developers and end-users.
Install Open-WebUI
You can install Open Web UI, using docker or pip.
You can follow instruction from official documentation
To install open web UI using pip
Open your terminal and run the following command:
pip install open-webui
Once installed, start the server using:
open-webui serve
After installation, you can access Open Web UI at http://localhost:8080.
If you want to run the open web UI using docker then use the following compose file.
services:
open-webui:
image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main}
container_name: open-webui
volumes:
- open-webui:/app/backend/data
ports:
- ${OPEN_WEBUI_PORT-3000}:8080
environment:
- 'OLLAMA_BASE_URL=http://host.docker.internal:11434'
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
ollama: {}
open-webui: {}
You can also run ollama and open-webUI using docker by using following docker compose file.
services:
ollama:
volumes:
- ollama:/.ollama
container_name: ollama
pull_policy: always
tty: true
restart: unless-stopped
image: ollama/ollama:${OLLAMA_DOCKER_TAG-latest}
open-webui:
image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main}
container_name: open-webui
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama
ports:
- ${OPEN_WEBUI_PORT-3000}:8080
environment:
- 'OLLAMA_BASE_URL=http://ollama:11434'
- 'WEBUI_SECRET_KEY='
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
ollama: {}
open-webui: {}
You can start the open-webui application using docker compose command.
docker-compose up -d
Once the container starts, you can access the open web UI at http://localhost:3030
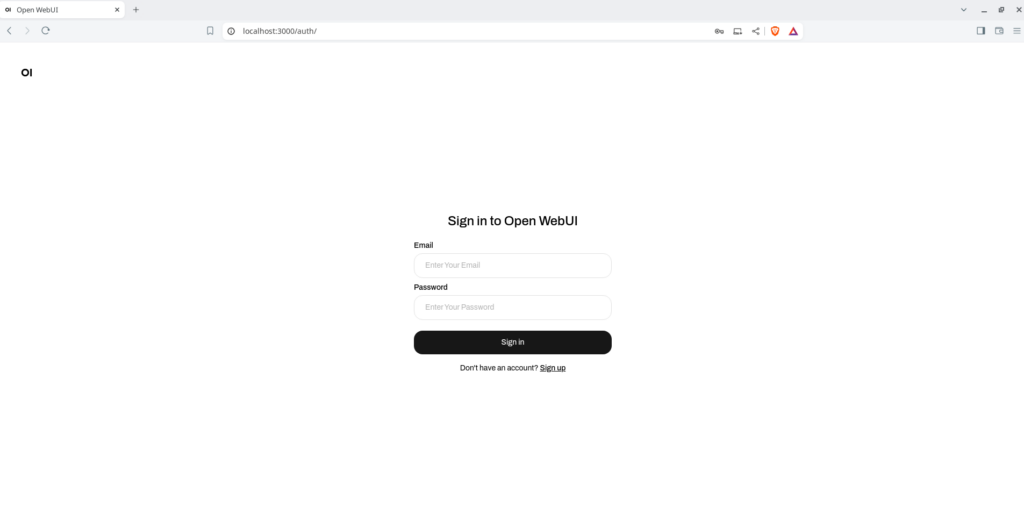
The open web UI interface shows login/sign up page. TO chat with LLM models you need to first signup with email/password.
The first user you create will get admin rights and the admin can create additional users.
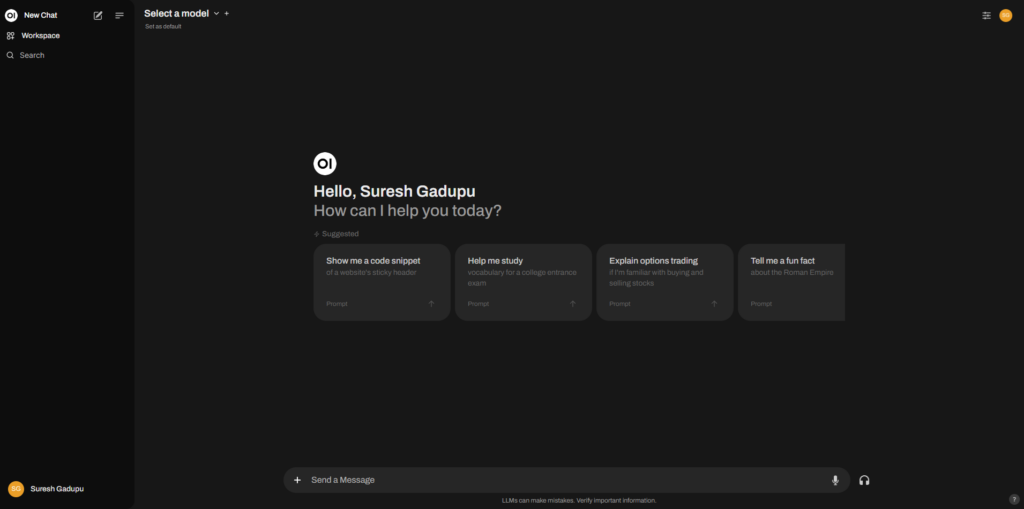
Once you login, you can see chat interface.
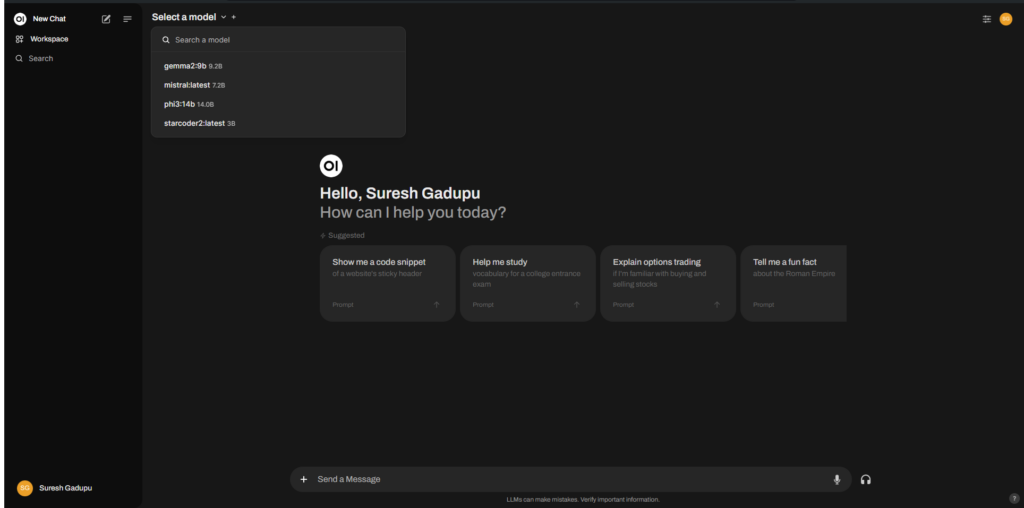
Next select the LLM model, you want to interact chat with. ( you need to download models with Ollama CLI)
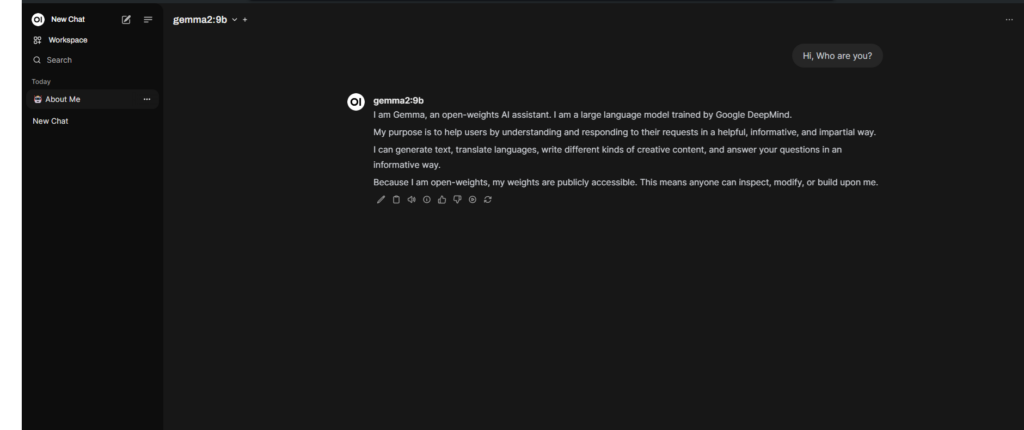
Next start asking questions to the model.
For better answers from LLMs, provide system prompt in the settings
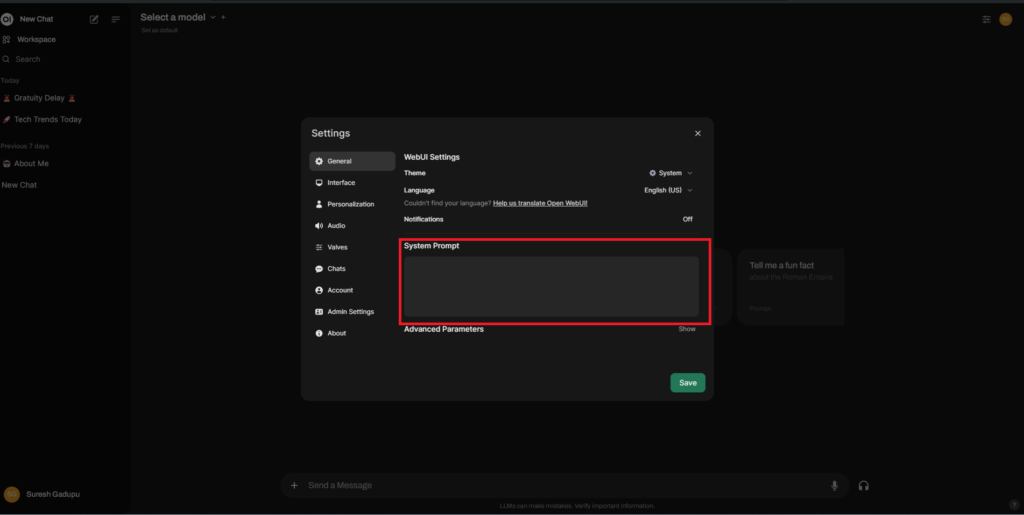
You can get system prompts from https://github.com/mustvlad/ChatGPT-System-Prompts
Importing the new models
If you want to try new LLM model other than models available on Ollama library, binary GGUF file can be imported directly into Ollama through a Modelfile.
First download the GGUF model file of LLM from huggingface
Then write model file like below
FROM /path/to/file.gguf
For example, I am trying to import mistral nemo model into my local LLM
FROM /mnt/seagate/Mistral-Nemo-Instruct-2407.Q4_K_M.gguf
Then using ollama cli run following command to import model file.
ollama create <model-name> -f <model-file-name>

You can also import models with following architectures
- LlamaForCausalLM
- MistralForCausalLM
- GemmaForCausalLM
You can also find more details on importing models in the following link.