How to update large number of records in batches in PostgreSQL
Recently at my work added a new column to two of our database tables and the newly introduced column had to updated based on the sequence number. These tables had millions of records.
Before updating records in huge numbers, we need to understand the little of PostgreSQL memory architecture.
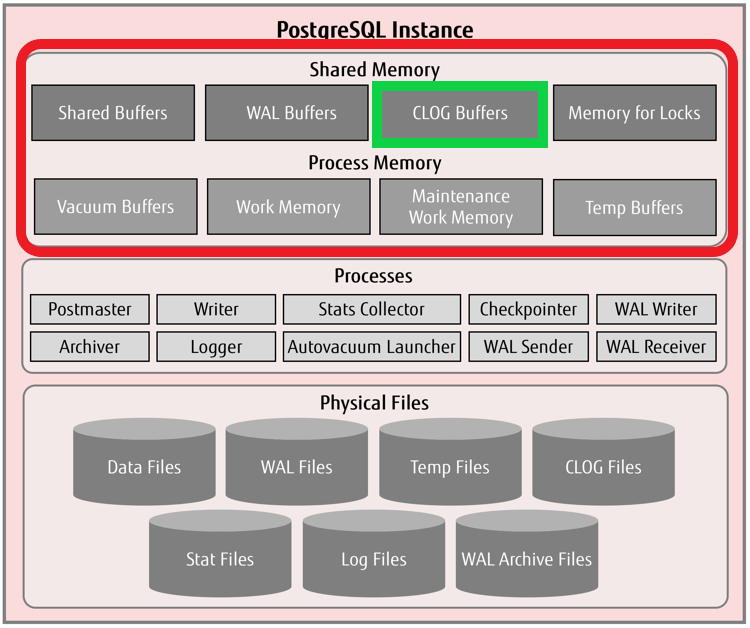
All the memory components which are enclosed in red rectangle are allocated in the RAM.
Shared Buffers
A database server also needs memory for quick access to data, whether it is READ or WRITE access. In PostgreSQL, this is referred to as “shared buffers” and is controlled by the parameter shared_buffers. The amount of RAM required by shared buffers is always locked for the PostgreSQL instance during its lifetime. The shared buffers are accessed by all the background server and user processes connecting to the database.
WAL Buffers
The write ahead log (WAL) buffers are also called “transaction log buffers”, which is an amount of memory allocation for storing WAL data. This WAL data is the metadata information about changes to the actual data, and is sufficient to reconstruct actual data during database recovery operations. The WAL data is written to a set of physical files in persistent location called “WAL segments” or “checkpoint segments”.The WAL buffers memory allocation is controlled by the wal_buffers parameter, and it is allocated from the operating system RAM
CLOG Buffers
CLOG stands for “commit log”, and the CLOG buffers is an area in operating system RAM dedicated to hold commit log pages. The commit log pages contain log of transaction metadata and differ from the WAL data. The commit logs have commit status of all transactions and indicate whether or not a transaction has been completed (committed).There is no specific parameter to control this area of memory. This is automatically managed by the database engine in tiny amounts.
Memory for Locks / Lock Space
This memory component is to store all heavyweight locks used by the PostgreSQL instance. These locks are shared across all the background server and user processes connecting to the database. A non-default larger setting of two database parameters namely max_locks_per_transaction and max_pred_locks_per_transaction in a way influences the size of this memory component
Since these buffers are allocated in RAM, there is limited amount of memory available for each buffer.
In my previous experience, when I had to update huge no of records in a single query, I faced CLOG buffer overflow problem as the szie of the buffer is very small.
When we try to update huge records in DB, we might also face problems like
- Query Time out
- Table deadlock
I had to find a way to update the records in batches to avoid the above problems. I came across blog post addressing exactly my problem. But in the post, blogger used the Ruby script to update the records in batches. In our production environment, we did not have the option to run any programming script, so we had to find a way to update records with SQL script only.
I have used the temporary table approach and written a procedure to update records in batches.
Let’s see the script with an example.
I am creating an Employee table
CREATE TABLE IF NOT EXISTS "Employee"."Employee"
(
id integer NOT NULL,
name character varying(200) NOT NULL,
authentication_key character varying(100),
CONSTRAINT "Employee_pkey" PRIMARY KEY (id)
);Code language: SQL (Structured Query Language) (sql)Let’s insert some data into the table. I am inserting only Id and Name fields and will update authentication_key field in batches
Insert into "Employee"."Employee"(id,name,authentication_key) Values
(1,'A',null),
(2,'B',null),
...
(24,'X',null),
(25,'Y',null),
(26,'Z',null);Code language: SQL (Structured Query Language) (sql)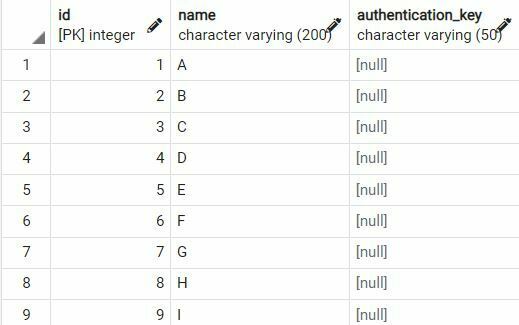
Now let’s create temp table
CREATE TEMP TABLE emp_auth_to_be_updated AS
SELECT ROW_NUMBER() OVER(ORDER BY id) row_id, id
FROM "Employee"."Employee"
WHERE authentication_key is null ;Code language: SQL (Structured Query Language) (sql)Temp table holds all the IDs where authentication_key is null.
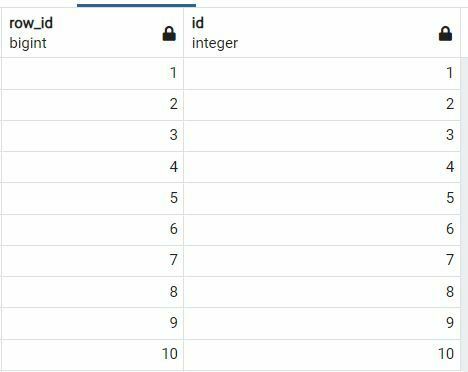
Now let’s develop a procedure which updates records in batches. Below procedure updates the records in batches of 5 records.
CREATE OR REPLACE PROCEDURE "Employee".update_auth_token()
LANGUAGE plpgsql
AS $$
DECLARE
-- variable declaration
total_records int;
batch_size int:=5;
counter int:=0;
BEGIN
SELECT INTO total_records COUNT(*) FROM "Employee"."Employee" e WHERE
authentication_key is NULL;
RAISE INFO 'Total records to be updated %', total_records ;
WHILE counter <= total_records LOOP
UPDATE "Employee"."Employee" emp
SET authentication_key = encode(gen_random_bytes(32), 'base64')
FROM emp_auth_to_be_updated eatbu
WHERE eatbu.id = emp.id
AND eatbu.row_id > counter AND eatbu.row_id <= counter+batch_size;
COMMIT;
counter := counter+batch_size;
END LOOP ;
END;
$$;Code language: Java (java)Note : gen_random_bytes method is not available by default in PostgreSQL.You need to enable pgcrypto module by running the below command
create extension if not exists pgcrypto;Code language: SQL (Structured Query Language) (sql)Let’s execute the procedure
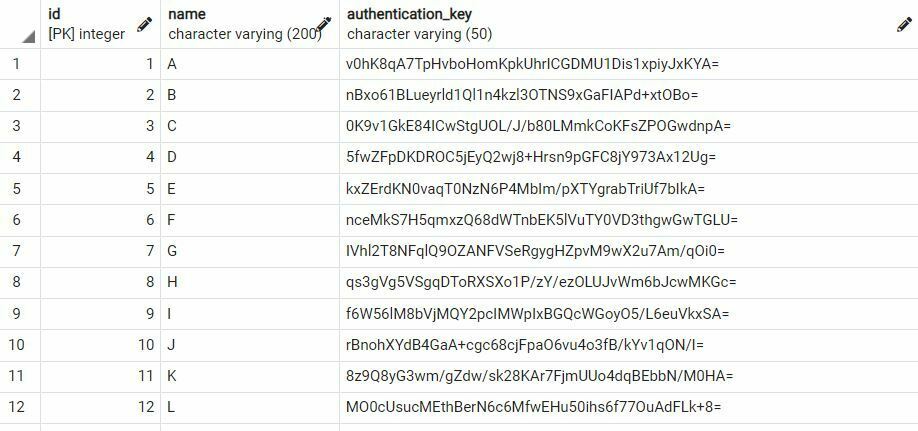
call "Employee".update_auth_token();Code language: Java (java)Now Let’s look Employee table now and you can see that authentication_key is field is populated.
You can get complete script for blog post from Github